Abstract
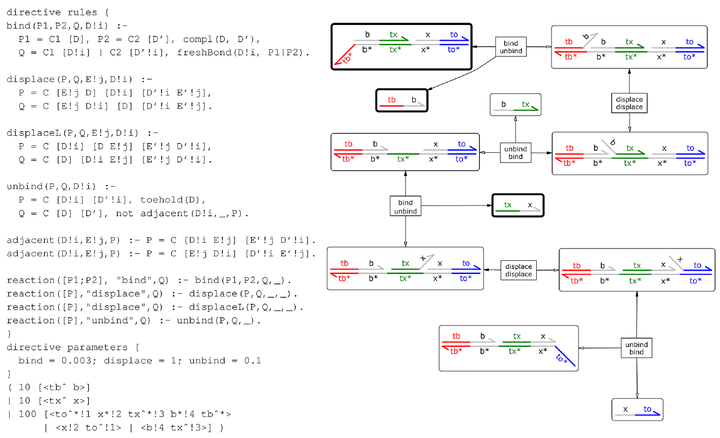
Computational nucleic acid devices show great potential for enabling a broad range of biotechnology applications, including smart probes for molecular biology research, in vitro assembly of complex compounds, high-precision in vitro disease diagnosis and, ultimately, computational theranostics inside living cells. This diversity of applications is supported by a range of implementation strategies, including nucleic acid strand displace- ment, localization to substrates, and the use of enzymes with poly- merase, nickase, and exonuclease functionality. However, existing computational design tools are unable to account for these strategies in a unified manner. This paper presents a logic programming lan- guage that allows a broad range ofcomputational nucleic acid systems to be designed and analyzed. The language extends standard logic programming with a novel equational theory to express nucleic acid molecular motifs. It automatically identifies matching motifs present in the full system, in order to apply a specified transformation expressed as a logical rule. The language supports the definition of logic predicates, which provide constraints that need to be satisfied in order for a given rule to be applied. The language is sufficiently expressive to encode the semantics of nucleic strand displacement systems with complex topologies, together with computation performed by a broad range of enzymes, and is readily extensible to new implementation strategies. Our approach lays the foundation for a unifying framework for the design of computational nucleic acid devices.